Introduction
Briefly introduce the purpose of the report and the two DBMSs to be discussed, explaining why they were selected and what the report will cover.
What is SQLite?
SQLite is a software library that provides a relational database management system. The lite in SQLite means lightweight in terms of setup, database administration, and required resources.
SQLite has the following noticeable features: self-contained, serverless, zero-configuration, transactional.
Serverless
Normally, an RDBMS such as MySQL, PostgreSQL, etc., requires a separate server process to operate. The applications that want to access the database server use TCP/IP protocol to send and receive requests. This is called client/server architecture.
The following diagram illustrates the RDBMS client/server architecture:
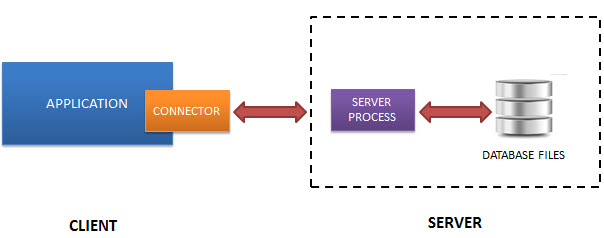
SQLite does NOT work this way.
SQLite does NOT require a server to run.
SQLite database is integrated with the application that accesses the database. The applications interact with the SQLite database read and write directly from the database files stored on disk.
The following diagram illustrates the SQLite server-less architecture:
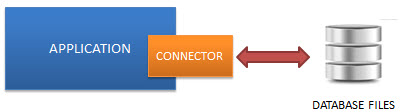
Self-Contained
SQLite is self-contained means it requires minimal support from the operating system or external library. This makes SQLite usable in any environment especially in embedded devices like iPhones, Android phones, game consoles, handheld media players, etc.
SQLite is developed using ANSI-C. The source code is available as a big sqlite3.c and its header file sqlite3.h. If you want to develop an application that uses SQLite, you just need to drop these files into your project and compile it with your code.
Zero-configuration Because of the serverless architecture, you don’t need to “install” SQLite before using it. There is no server process that needs to be configured, started, and stopped.
In addition, SQLite does not use any configuration files.
Others features of Sqlite
- Transactions are atomic, consistent, isolated, and durable (ACID) even after system crashes and power failures.
- Zero-configuration - no setup or administration needed.
- Full-featured SQL implementation with advanced capabilities like partial indexes, indexes on expressions, JSON, common table expressions, and window functions. (Omitted features)
- A complete database is stored in a single cross-platform disk file. Great for use as an application file format.
- Supports terabyte-sized databases and gigabyte-sized strings and blobs. (See limits.html.)
- Small code footprint: less than 750KiB fully configured or much less with optional features omitted.
- Simple, easy to use API.
- Fast: In some cases, SQLite is faster than direct filesystem I/O
- Written in ANSI-C. TCL bindings included. Bindings for dozens of other languages available separately.
- Well-commented source code with 100% branch test coverage.
- Available as a single ANSI-C source-code file that is easy to compile and hence is easy to add into a larger project.
- Self-contained: no external dependencies.
- Cross-platform: Android, *BSD, iOS, Linux, Mac, Solaris, VxWorks, and Windows (Win32, WinCE, WinRT) are supported out of the box. Easy to port to other systems.
- Sources are in the public domain. Use for any purpose.
- Comes with a standalone command-line interface (CLI) client that can be used to administer SQLite databases.
One of the key features of SQLite is its support for indexing, query processing, and query optimization. Indexing is a technique that allows for faster searching and retrieval of data by creating a data structure that maps column values to their corresponding rows in the table. SQLite supports multiple types of indexes, including B-tree, Hash, and R-tree indexes, which can be used to speed up searches and retrievals of data.
Query processing in SQLite involves parsing and analyzing SQL statements, optimizing query plans, and executing queries using various algorithms and techniques. SQLite employs a cost-based query optimizer that uses statistical information about the database and table schema to choose the most efficient query plan. This optimizer takes into account the size and complexity of the tables, the distribution of data in the tables, and the types of operations being performed to determine the most efficient way to execute the query.
Query optimization is an important part of SQLite's query processing capabilities, as it can greatly improve the performance and efficiency of database operations. By optimizing queries, SQLite can reduce the amount of time and resources required to process data, resulting in faster response times and better overall performance.
Overall, SQLite's support for indexing, query processing, and query optimization make it a powerful and efficient tool for managing data in a wide range of applications. Whether you're developing a mobile app, a web application, or an embedded system, SQLite's lightweight architecture and powerful features make it an excellent choice for managing and processing data.
How about Redshift ?
Indexing
Explain the different types of indexing supported by Sqlite, such as B-tree and hash indexes, and their advantages and disadvantages. Discuss how indexing can improve query performance by reducing the number of disk I/O operations needed to access data.cDemonstrate the use of indexing in optimizing queries, with at least two examples, such as finding all orders for a particular customer or finding all products with a specific price.
SQLite
What is an index?
In relational databases, a table is a list of rows. In the same time, each row has the same column structure that consists of cells. Each row also has a consecutive rowid sequence number used to identify the row. Therefore, you can consider a table as a list of pairs: (rowid, row).
Unlike a table, an index has an opposite relationship: (row, rowid). An index is an additional data structure that helps improve the performance of a query.
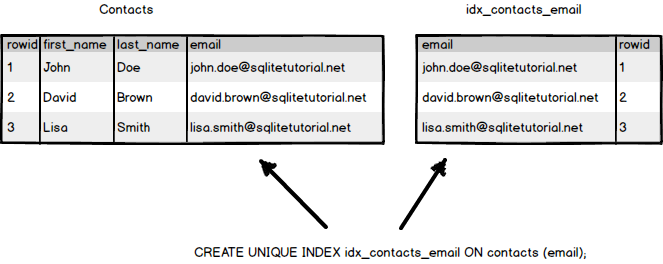
Sqlite includes B-Tree indexes, Hash indexes and R-Tree indexes
- B-tree Indexes: B-tree indexes are the most commonly used index type in SQLite. They work by storing the indexed column values in a tree structure, with each node in the tree containing a range of values and pointers to child nodes. B-tree indexes are efficient for range queries
SELECT * FROM table WHERE column BETWEEN value1 AND value2
as they allow for efficient retrieval of all rows within a specified range. They are also efficient for sorting and ordering data, making them a good choice for ORDER BY queries. However, B-tree indexes can be slow for queries that involve equality comparisons (e.g., SELECT * FROM table WHERE column = value), as the entire index must be searched for a matching value.
-
Hash Indexes: Hash indexes work by hashing the indexed column values to generate a unique identifier that is used to look up rows in the table. Hash indexes are very fast for equality comparisons, making them a good choice for queries that involve lookups of a single value (e.g., SELECT * FROM table WHERE column = value). However, hash indexes are not well-suited for range queries or ordering data, as the hash function does not preserve the order of the indexed values.
-
R-tree Indexes: R-tree indexes are used for spatial data and allow for efficient searching of geometric data such as points, lines, and polygons. R-tree indexes work by organizing the indexed data into a hierarchical structure of rectangles, with each node in the tree containing a rectangle and pointers to child nodes. R-tree indexes are efficient for range queries and can also support complex queries involving spatial relationships between objects. However, R-tree indexes can be slow to update, as changes to the indexed data require rebuilding the entire index.
B-tree indexes
The B-tree keeps the amount of data at both sides of the tree balanced so that the number of levels that must be traversed to locate a row is always in the same approximate number. In addition, querying using equality (=) and ranges (>, >=, <,<=) on the B-tree indexes are very efficient.
Each index must be associated with a specific table. An index consists of one or more columns, but all columns of an index must be in the same table. A table may have multiple indexes.
Whenever you create an index, SQLite creates a B-tree structure to hold the index data.
The index contains data from the columns that you specify in the index and the corresponding rowid value. This helps SQLite quickly locate the row based on the values of the indexed columns.
Imagine an index in the database like an index of a book. By looking at the index, you can quickly identify page numbers based on the keywords.
To create an index, you use the CREATE INDEX statement with the following syntax:
CREATE [UNIQUE] INDEX index_name
ON table_name(column_list);
Note: In case you want to make sure that values in one or more columns are unique like email and phone, you use the UNIQUE option in the CREATE INDEX statement. The CREATE UNIQUE INDEX creates a new unique index.
Using a B-tree index for all indexes in SQLite provides several advantages:
Simplicity: Having a single index type simplifies the codebase and reduces the complexity of the SQLite database engine.
Familiarity: Because B-trees are a well-known and widely used data structure, many developers are already familiar with how they work and how to optimize queries that use them.
Flexibility: B-trees are a flexible data structure that can be used to support a wide range of query types, including range queries and exact-match queries.
Efficiency: B-trees are highly efficient for both insertions and lookups, making them a good choice for indexing data in a relational database like SQLite.
Overall, using a B-tree index for all indexes in SQLite provides a simple, flexible, and efficient way to index data and improve query performance.
The use of indexing in optimizing queries, with at least two examples, such as finding all orders for a particular customer or finding all products with a specific price.
*** DEMO 4 types of queries ***